As detailed in my most recent post Retrieving bulk twitter data, I am going to need to use scraping to get enough tweet data for my project. On the surface it appears this might present some problems, as Twitter’s Terms of Service assert that it I may not scrape the Twitter website:
… scraping the Services without the prior consent of Twitter is expressly prohibited
They also assert that the Terms of Service apply to anyone accessing their services:
These Terms of Service (“Terms”) govern your access to and use of our services, including our various websites, SMS, APIs, email notifications, applications, buttons, widgets, ads, commerce services, and our other covered services (https://support.twitter.com/articles/20172501) that link to these Terms (collectively, the “Services”), and any information, text, links, graphics, photos, audio, videos, or other materials or arrangements of materials uploaded, downloaded or appearing on the Services (collectively referred to as “Content”). By using the Services you agree to be bound by these Terms.
This has also been raised as an issue for users of the twitterscraper Python package I used in the previous post (see issues #60, #110 and #112).
If Twitter’s assertions are enforceable (i.e. if they have the right to impose these terms upon me) then this presents a significant impediment for my project!
Do I have to accept the Twitter Terms of Service?
In Australia it is unclear whether users of websites are bound by their Terms of Service, except where the user has expressly agreed to those terms - for example as part of an account creation or login process. There are some examples from the United States and European Union (see the Wikipedia summary) where courts have found that the Terms of Service do not prevent web scraping, and in Australia the only relevant law is the Spam Act (2003) which prohibits scraping for email addresses.
In one specific case in the United States (LinkedIn vs HiQ), a California federal court judge found that HiQ Labs were operating within the law when they scraped the publicly accessible sections of LinkedIn’s website. Whilst this ruling does not impact on the laws governing users in Australia, it seems unlikely that Australian lawmakers will move to outlaw web scraping any time soon. Ars Technica have an excellent write up of this case.
Fellow MDSI Student Passiona Cottee has prepared a summary of laws impacting upon web scraping in Australia, which summarises the following:
If website requires a log-in, it is unlikely T&Cs would be enforceable against a person who accesses the website without first having created an account (and therefore not expressly agreed to be bound by the T&Cs).
And more specifically, regarding copyright:
Newspaper articles, strings of words written by someone else, cannot be reproduced without attribution as this would also constitute infringement. However, your app/website can point to them and act as an index.
In summary, by using the twitterscraper Python package to obtain tweets, I do not believe I am in breach of any laws in Australia (where I am accessing the service) nor in the United States (where Twitter is based). I am complying with the requirements of Australian copyright law by attributing the strings of words to the users who wrote those words, and I will not be downloading any images (which would introduce more substantial copyright issues).
Is it ethical to scrape Twitter for this project?
Keeping in mind that this project is non-commercial and academic, I feel like my use of scraping to obtain data would pass the “pub test”, which is evidently the highest benchmark for ethical practice in Australia. More formally though, there are a few groups of stakeholders to consider here:
Twitter provide a free service to users, and they monetise that service through advertising and selling access to their data. My project is not going to impact in any way on their advertising revenue - if anything it will increase engagement in the R community, which will increase their advertising impressions. My impact upon Twitter’s data sale business is less clear cut, but as I am a student doing a non-commercial project, and I will not be on-selling the data that I scrape, I do not consider my actions to be harming Twitter.
Tweet authors
People who tweet publicly in the R community do so in the full knowledge that their tweets will be read by others in the R community. I will not be impacting upon their rights or expectations under copyright, and will only be using their tweet content with attribution. Further, the tweet authors have explicitly accepted the Twitter Terms of Service which means that Twitter can sell their tweet data to whoever they like. The impact of my project accessing their tweet data is negligible in this context.
Me
I’m not making any profit from this project, and I need data in order to fulfil the requirements of my university project. I would happily pay a reasonable price to obtain this data, but I do not have $80,000 to spend on data extraction!
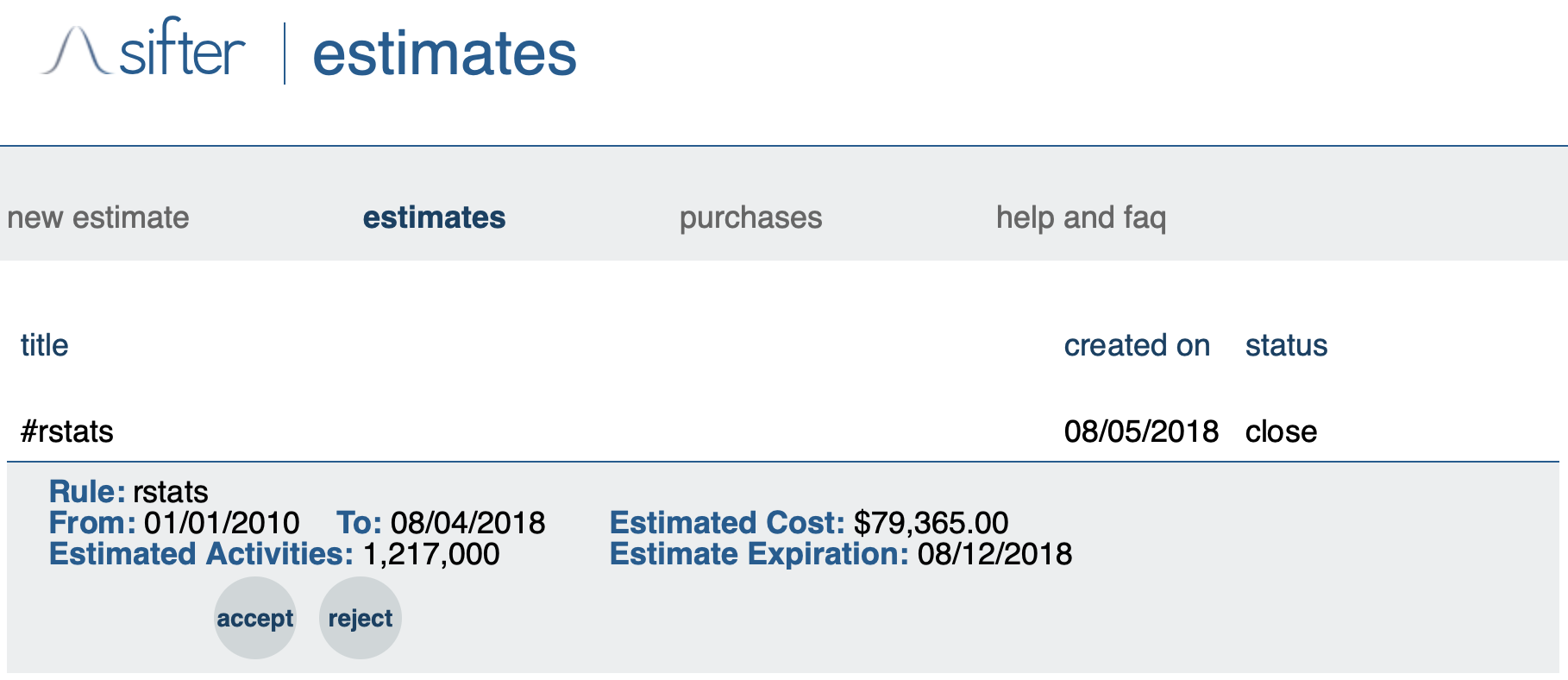
Summary
Based on the limited legal precedent available in Australia and the United States, I believe that I am legally able to use tools like the twitterscraper Python package to search for and collect tweets for this project. I have also considered the ethical implications of this for all key stakeholders, and concluded that it is ethically acceptable for me to continue with my plan to use scraping as my main data collection method.