One of the potential challenges for my project is getting enough data. The rtweet package lets me retrieve 18,000 tweets at a time (limited by the Twitter API rate limit), which is more than enough for ongoing analysis. The more challenging part of the process is getting access to older tweets, because the Twitter API only returns data from the past 7 days.
To get access to more data, I have a few options:
- Pay Twitter for an enterprise account with API access to the full Twitter history
- Pay a third-party (who already has enterprise API access with Twitter) to extract the data
- Creatively reconstruct the timeline by crawling from known participants
- Screen scape like I’ve never screen scraped before
I actually considered all four of these options, and concluded:
- Twitter are kidding themselves with their pricing. It is outrageous, and because they consider academics as one of their target markets, there are no student discounts.
- An estimate for the purchase of #rstats tweets since January 1st 2010 (via Sifter which told me that I’m going to need to extract about 1.2 million tweets) came to US$80,000 which is obviously more than I am willing to pay for a uni project, or any project ever. And that doesn’t even consider all of the other hashtags I would want to extract!
- I could probably reconstruct the majority of the #rstats timeline by finding everyone that tweeted in the last 7 days, finding all of their tweets, everyone they follow/mention/retweet, and then repeating all the way back to the start of recorded Twitter history (21 March 2006). This would be a good way to “crawl” through the whole R community (the ones on Twitter anwyay) but is likely infeasible due to the Twitter API rate limit. It’s a good idea to keep in the back pocket though!
- Screen scraping can take ages if done “manually”, but there is a saviour in the form of Ahmet Taspinar’s twitterscraper Python package. This package uses standard Python web scraping approaches (via Beautiful Soup and Requests) to extract tweets using multiple HTTP requests in parallel. There are some questions about the legality and ethics of screen scraping, which I will discuss in my next post. For now, it is enough to note that it is possible and it looks like the answer to all of my problems.
Scraping Twitter for #rstats
Regardless of the fact this project is explicitly focused on the R community, no one has written a Twitter scraper in R so it looks I’m using Python for this part of the project. The tool does come with a Command Line Interface (CLI) so I’ll be using that because it’s easier than diving into Python.
The following bash command searches for tweets with the #rstats hashtag, using 20 simultaneous connections, and stops when approximately 10,000 have been found. It then exports them to a CSV file.
twitterscraper '#rstats' --limit=10000 --output=/Users/perrystephenson/tweets.csv --csvWe can now load the tweets into R and see how they look.
library(tidyverse)
tweets <- read_csv("/Users/perrystephenson/tweets.csv")
tweets %>% select(fullname, text)## # A tibble: 7,764 x 2
## fullname text
## <chr> <chr>
## 1 Josh Reich Next NY R Meetup - High Performance Computing with R…
## 2 Drew Conway Finalized: next NYC #rstats #meetup will be held Thu…
## 3 Rense Nieuwenhuis Yes! My application for presenting influence.ME at t…
## 4 Rense Nieuwenhuis Translating a book on statistics, writing manual for…
## 5 Matt Parker For my R people: http://learnr.wordpress.com/ looks …
## 6 datayoda Tried to learn some R #rstats today. I just don't ge…
## 7 Rense Nieuwenhuis #Rstats: This bugs me: why do I get different result…
## 8 Jeff Horner Just recommended brew for #rstats when someone else …
## 9 Michael E. Drisc… Tonite's R Users Meetup: Building Web Dashboards w/ …
## 10 Drew Conway I am equal parts infuriated and fascinated by having…
## # ... with 7,754 more rowsIt worked! We only have 7764 rows due to the way the limit is implemented, but that is okay for now. When we get rid of the limit term it will collect all available tweets. For now, we can take a look at the tweets that have been collected.
num_days <- max(as.Date(tweets$timestamp)) - min(as.Date(tweets$timestamp)) + 1
ggplot(tweets, aes(x = as.Date(timestamp))) +
geom_histogram(bins = num_days)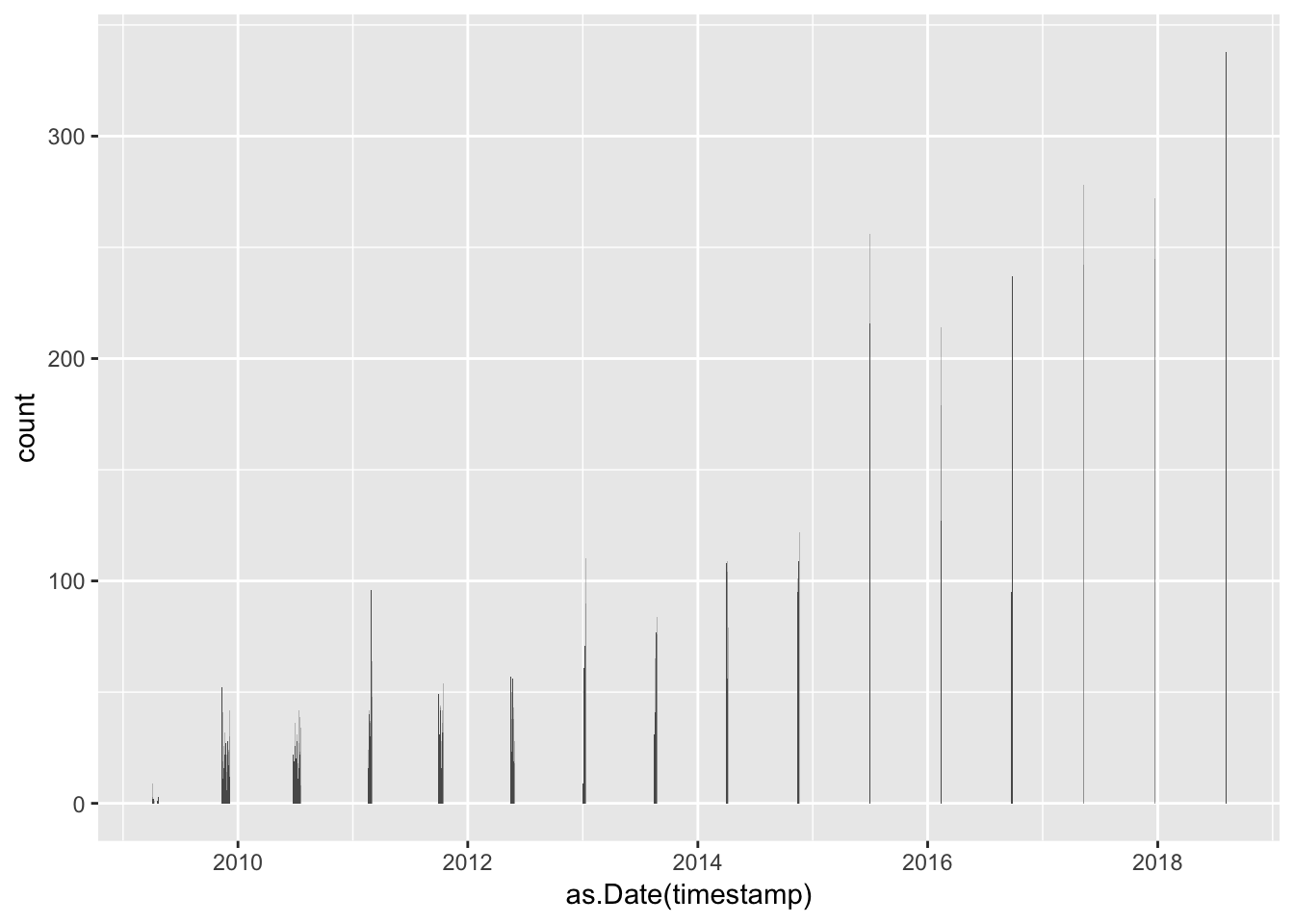
This shows how the twitterscraper package works - it has spawned 20 separate sessions with their own date range (the default value for the --poolsize argument is 20), and has extracted tweets from each of those sessions until it hit the tweet limit. In theory I can have as many sessions as my internet connection will allow, and the date range for each of those sessions will be progressively smaller as the number of sessions is increased.
To collect all #rstats tweets using 300 sessions, I have used the following command:
twitterscraper '#rstats' --all --poolsize=300 --output=/Users/perrystephenson/all_tweets.csv --csvtweets <- read_csv("/Users/perrystephenson/all_tweets.csv")
num_days <- max(as.Date(tweets$timestamp)) - min(as.Date(tweets$timestamp)) + 1
ggplot(tweets, aes(x = as.Date(timestamp))) +
geom_histogram(bins = num_days)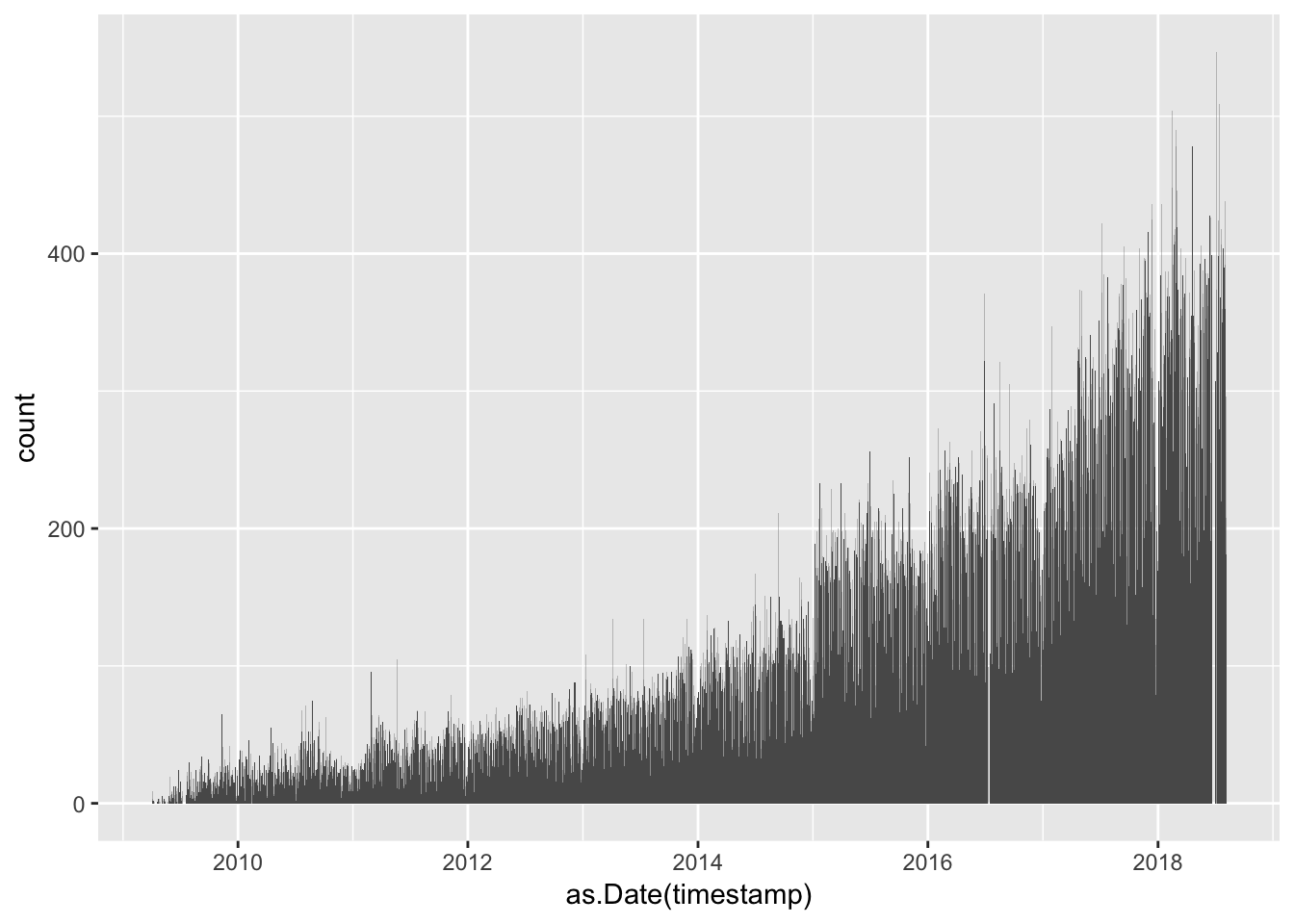
There are two small gaps in the tweet record here - one in the middle of 2016 and another around May 2018. I’ve tried a bunch of different approaches for resolving this, and it turns out that the most robust way to collect all of the tweets is to make multiple calls with smaller date ranges. Accordingly, I wrote a little bash script to grab all of the tweets for #rstats:
#!/bin/bash
dates=(2006-01-01 2007-01-01 2008-01-01 2009-01-01 2010-01-01 2011-01-01 \
2012-01-01 2013-01-01 2014-01-01 2015-01-01 2016-01-01 2017-01-01 \
2018-01-01 2019-01-01)
for i in {0..12}
do
FILENAME="$(echo rstats_tweets_${dates[$i]}| cut -d'-' -f 1).csv"
twitterscraper '#rstats' --begindate=${dates[$i]} --enddate=${dates[$i+1]} \
--output=/Users/perrystephenson/data/twitter-demo/$FILENAME --csv --poolsize=50
doneThis gave me one file per year, and when loaded into R it is easy to confirm that all of the tweets are indeed present.
file_names <- list.files("~/data/twitter-demo", full.names = TRUE)
tweet_files <- vector(mode = "list", length = length(file_names))
for (i in seq_along(file_names)) {
tweet_files[[i]] <- read_csv(file_names[i])
}
tweets <- bind_rows(tweet_files)num_days <- max(as.Date(tweets$timestamp)) - min(as.Date(tweets$timestamp)) + 1
ggplot(tweets, aes(x = as.Date(timestamp))) +
geom_histogram(bins = num_days)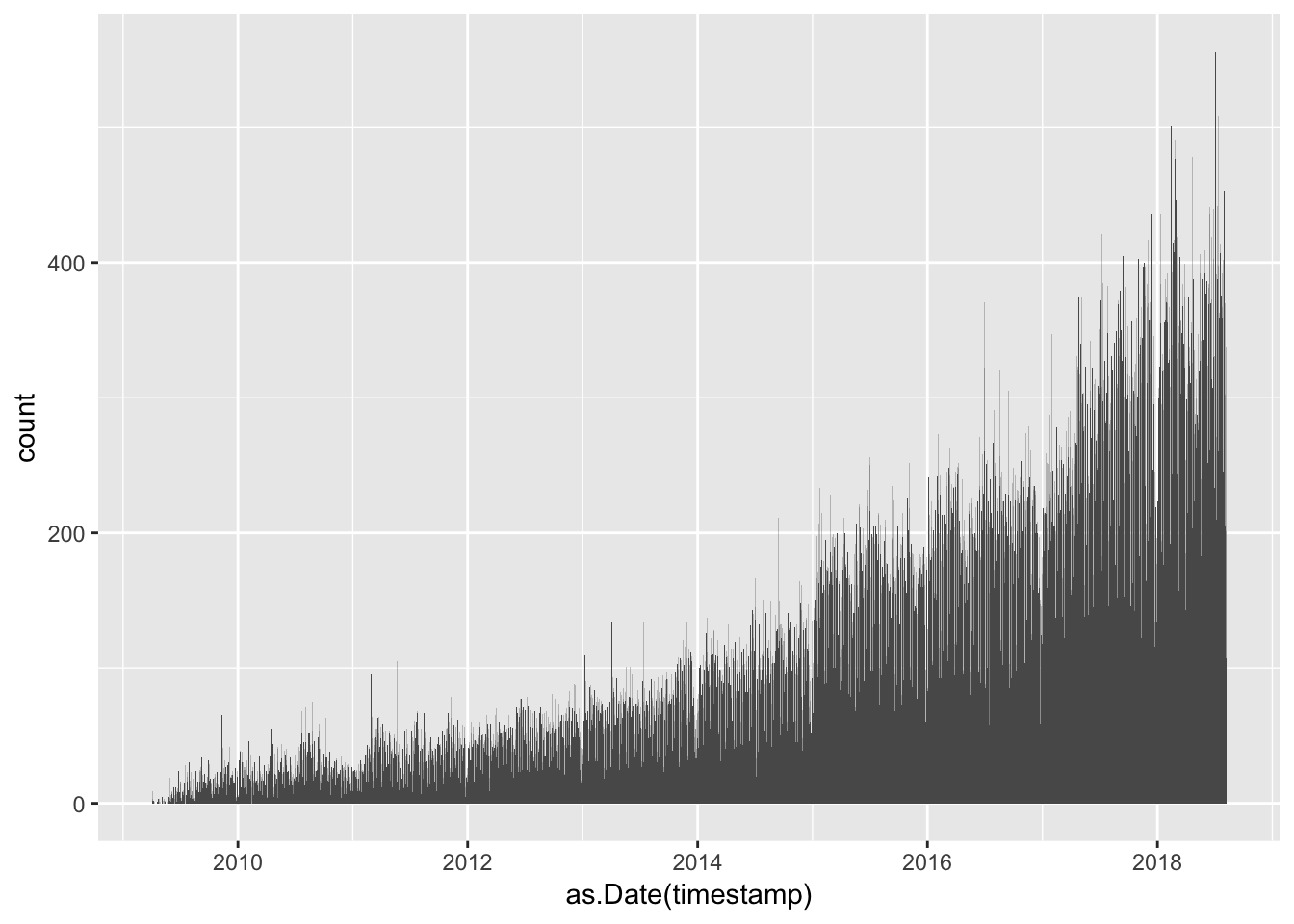
Now that I have a viable method for collecting tweets, I can proceed with the project! Taken to the obvious extreme conclusion, I can now loop through all of my hashtags and collect all of the data I need for my project.
#!/bin/bash
dates=(2006-01-01 2007-01-01 2008-01-01 2009-01-01 2010-01-01 2011-01-01 \
2012-01-01 2013-01-01 2014-01-01 2015-01-01 2016-01-01 2017-01-01 \
2018-01-01 2019-01-01)
hashtags='rstats rladies r4ds user2008 user2009 user2010 user2011 user2012
user2013 user2014 user2015 user2016 user2017 user2018 user2019
user2020 user2021 tidyverse hadleyverse rcpp bioconductor ggplot
datacamp ropensci'
for ht in $hashtags
do
for i in {0..12}
do
FILENAME="$(echo ${ht}_tweets_${dates[$i]}| cut -d'-' -f 1).csv"
SEARCH="#$(echo ${ht})"
twitterscraper $SEARCH --begindate=${dates[$i]} --enddate=${dates[$i+1]} \
--output=/Users/perrystephenson/data/twitter/$FILENAME --csv --poolsize=50
done
done