In a previous blog post I wrote about scraping Twitter to get 400,000 tweets about R as part of my capstone project at the University of Technology, Sydney. I’ve got some big plans for network analysis with this dataset, but before I start untangling hairballs I thought I might as well take a look for any interesting stories that can help me understand the structure of the the R Twitter community.
library(tidyverse)
library(tidytext)
library(glue)
library(kableExtra)
tweets <- readRDS("~/data/twitter-cache/tweets.rds")What are the top hashtags in the R community?
This first piece of analysis is fairly self-explanatory - what hashtags are people using when they tweet about R?
hashtags <- tweets %>%
unnest_tokens(word, text, "tweets") %>%
filter(str_detect(word, "^#"))
hashtags %>%
count(word, sort=T) %>%
top_n(10) %>%
ggplot(aes(x = fct_reorder(word, n), y = n)) +
geom_col(fill = "red") +
labs(title = "Top 10 R Hashtags",
subtitle = "March 21 2006 to August 7 2018",
x = "Hashtag", y = "Tweets (all time)") +
coord_flip() +
theme_minimal()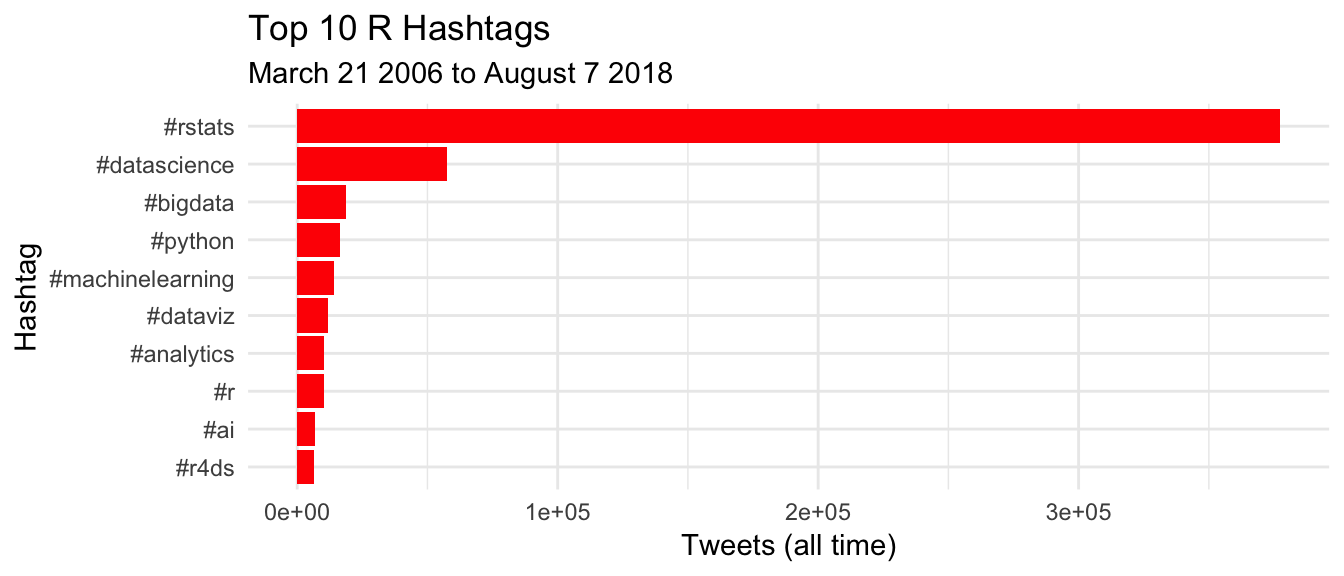
It is clear that #rstats is the center of the R community on Twitter! It looks like there is lots of cross-posting hashtags as well - I’ll take a look at this using tidygraph/ggraph in a later post.
When did the #rstats hashtag start to take off?
library(lubridate)
rstats <- hashtags %>%
filter(word == "#rstats") %>%
mutate(month = floor_date(timestamp, "months")) %>%
filter(month != ymd("2018-08-01")) # Incomplete month
ggplot(rstats, aes(x = month)) +
geom_bar(fill = "red") +
labs(title = "Tweet volume per month",
subtitle = "#rstats hashtag",
x = "Date (Month)", y = "Tweets") +
theme_minimal()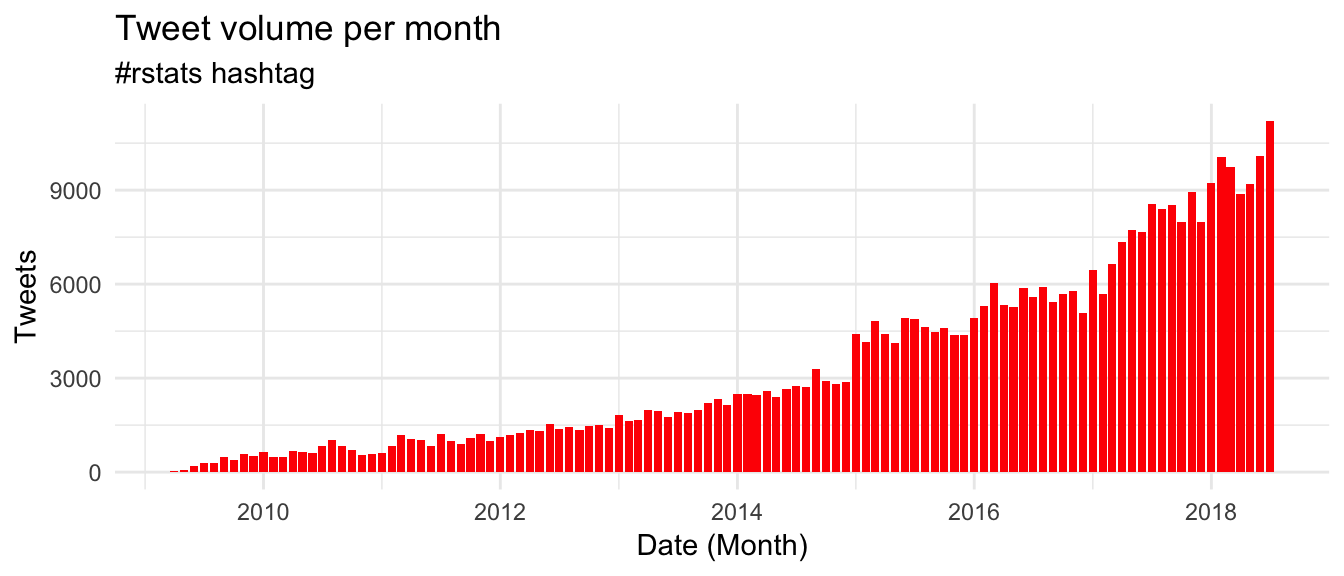
The first #rstats tweet was in April 2009, and was written by Drew Conway. I was interested to see how it all started, so I went and hunted down the tweets on the Twitter website
It’s always risky making public declarations, but it appears to have paid off for Drew.
How much do conferences influence the R discussion on Twitter?
For my next trick, I am going to look at the days with the highest volumes of Twitter activity in the R community, and then I’m going to find the most popular hashtag for each of those days. I’m expecting to see that most (if not all) of the busiest days in the R Twitter world are related to conference acvitity.
tweets_per_day <- tweets %>%
mutate(Date = date(timestamp)) %>%
count(Date, sort=T) %>%
rename("Total Tweets" = n)
top_hashtag_per_day <- hashtags %>%
mutate(Date = date(timestamp)) %>%
count(Date, word) %>%
group_by(Date) %>%
filter(n == max(n)) %>%
ungroup() %>%
rename("Dominant Hashtag" = word,
"Hashtag Tweets" = n)
tweets_per_day %>%
left_join(top_hashtag_per_day) %>%
top_n(10, `Total Tweets`) %>%
kable()| Date | Total Tweets | Dominant Hashtag | Hashtag Tweets |
|---|---|---|---|
| 2018-07-13 | 911 | #rstats | 539 |
| 2017-07-05 | 885 | #user2017 | 567 |
| 2016-06-28 | 879 | #user2016 | 588 |
| 2017-07-06 | 844 | #user2017 | 485 |
| 2018-07-12 | 832 | #user2018 | 466 |
| 2018-07-11 | 794 | #user2018 | 439 |
| 2016-06-29 | 725 | #user2016 | 467 |
| 2017-07-07 | 667 | #user2017 | 386 |
| 2018-07-05 | 572 | #rstats | 559 |
| 2018-07-10 | 570 | #rstats | 452 |
Seven of the top ten high activity days for the R community on Twitter were dominated by the UseR! conference, and nine out of ten days were conference days (and definitely boosted by the conference). Despite being the day before UseR! 2018, May 7th appears to be just a normal day of #rstats Twitter chat, with perhaps a slight bump in the number of bot messages due to package releases - maybe everyone was getting their packages updated in time for their UseR! talks! Either way, the UseR! conference is undoubtedly a key driver of activity in the R Twitter community.
It seems reasonable to assume that these conferences might be a “gateway” for new people joining the R Twitter community, but equally these volumes could be driven by existing users who enjoy live tweeting talks. Let’s take a look at the number of unique users on each day to see what’s really happening.
users_per_day <- tweets %>%
mutate(Date = date(timestamp)) %>%
select(user, Date) %>%
distinct() %>%
count(Date, sort=T) %>%
rename("Total Users" = n)
users_per_day %>%
left_join(top_hashtag_per_day) %>%
top_n(10, `Total Users`) %>%
kable()| Date | Total Users | Dominant Hashtag | Hashtag Tweets |
|---|---|---|---|
| 2018-07-13 | 381 | #rstats | 539 |
| 2017-07-06 | 365 | #user2017 | 485 |
| 2018-07-12 | 365 | #user2018 | 466 |
| 2018-07-11 | 356 | #user2018 | 439 |
| 2017-07-05 | 348 | #user2017 | 567 |
| 2016-06-29 | 333 | #user2016 | 467 |
| 2016-06-28 | 312 | #user2016 | 588 |
| 2018-07-10 | 311 | #rstats | 452 |
| 2018-02-14 | 305 | #rstats | 504 |
| 2018-08-01 | 298 | #rstats | 458 |
The UseR! conference certainly seems to be driving up the number of unique daily users in the R Twitter community, with the top 8 days being conference days. This doesn’t explain whether they are new users though, so let’s look into that now.
What drives people to join the R Twitter community?
By looking at a user’s first R tweet we can hopefully get an idea about what is driving growth in the community. We’ll drop the hashtags from this first table because we want to look at the content of their tweet, not their hashtags.
first_tweets <- tweets %>%
group_by(user) %>%
filter(timestamp == min(timestamp)) %>%
ungroup()
first_tweets %>%
unnest_tokens(word, text, "tweets") %>%
anti_join(stop_words) %>%
mutate(word = SnowballC::wordStem(word)) %>%
filter(!str_detect(word, "^#")) %>%
count(word, sort=T) %>%
top_n(10) %>%
kable()| word | n |
|---|---|
| data | 3363 |
| rt | 2414 |
| packag | 2004 |
| learn | 1809 |
| code | 1087 |
| analysi | 985 |
| de | 907 |
| time | 875 |
| im | 751 |
| model | 741 |
There is a bit of noise here, but it looks like retweeting is a very common way for people to start engaging with the community, and a lot of people mention learning. I think this needs a bit more work to be useful, but LDA (not shown) didn’t give me anything useful to work with so I think I’ll leave that for another day.
Now let’s look at hashtags in users’ “first R tweets”:
first_tweets %>%
unnest_tokens(word, text, "tweets") %>%
anti_join(stop_words) %>%
filter(str_detect(word, "^#")) %>%
count(word, sort=T) %>%
top_n(10) %>%
ggplot(aes(x = fct_reorder(word, n), y = n)) +
geom_col(fill = "red") +
labs(title = "First R Tweet",
subtitle = "Hashtags in each user's first R-related tweet",
x = "Hashtag", y = "Number of uses of the hashtag in users' first R tweets") +
coord_flip() +
theme_minimal()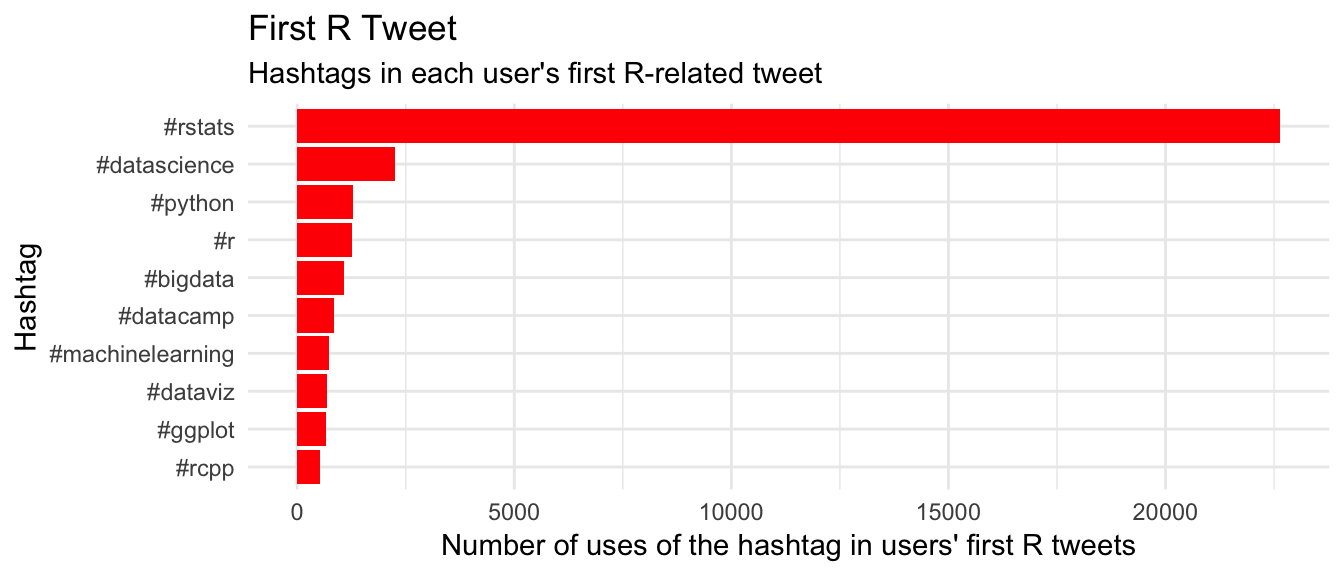
Interestingly, conference hashtags don’t even make the top 10 for first tweets. We can look for tweets with UseR! hashtags directly to see what’s going on:
first_tweets %>%
unnest_tokens(word, text, "tweets") %>%
anti_join(stop_words) %>%
filter(str_detect(word, "^#user20(09|1[0-8])")) %>%
count(word, sort=T) %>%
top_n(10) %>%
ggplot(aes(x = word, y = n)) +
geom_col(fill = "red") +
labs(title = "First R Tweet - Conferences",
subtitle = "Hashtags used by users who made their first R tweet about a conference",
x = "Hashtag", y = "Number of uses of the hashtag in users' first R tweets") +
coord_flip() +
theme_minimal()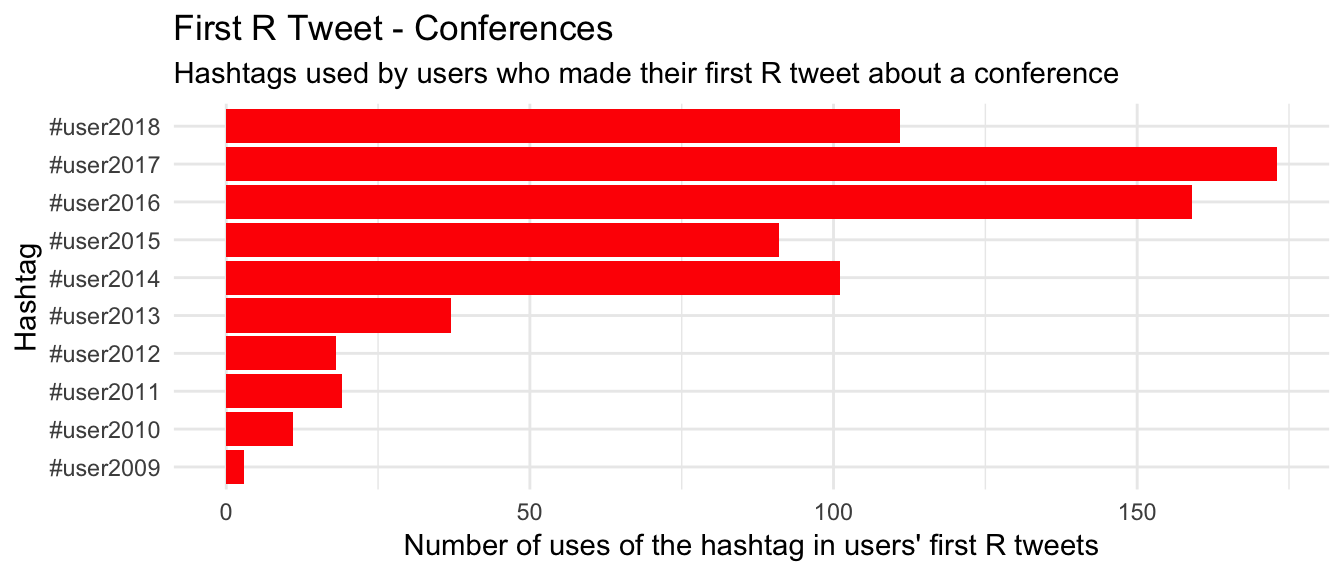
There are certainly a few new tweeters here, with recent conferences each bringing 100+ new users to the R Twitter community. We can look at how these “new tweeters” are impacting the overall volume of tweets at each conference.
user_origins <- first_tweets %>%
unnest_tokens(word, text, "tweets") %>%
anti_join(stop_words) %>%
mutate(conference = str_detect(word, "^#user[0-9]{4}")) %>%
group_by(user) %>%
summarise(Origin = if_else(any(conference), "Conference", "Something Else"))
tweets %>%
left_join(user_origins) %>%
unnest_tokens(word, text, "tweets") %>%
anti_join(stop_words) %>%
filter(str_detect(word, "^#user20(09|1[0-8])$")) %>%
ggplot(aes(x = word, fill = fct_rev(Origin))) +
geom_bar() +
labs(title = "Conference Tweets",
subtitle = "Tweet volumes at each of the 10 last UseR! conferences",
x = "Hashtag", y = "Tweets about each conference") +
coord_flip() +
scale_fill_manual(values = c("pink", "red"),
name = "User first joined\nthe R Twitter\ncommunity via...") +
theme_minimal()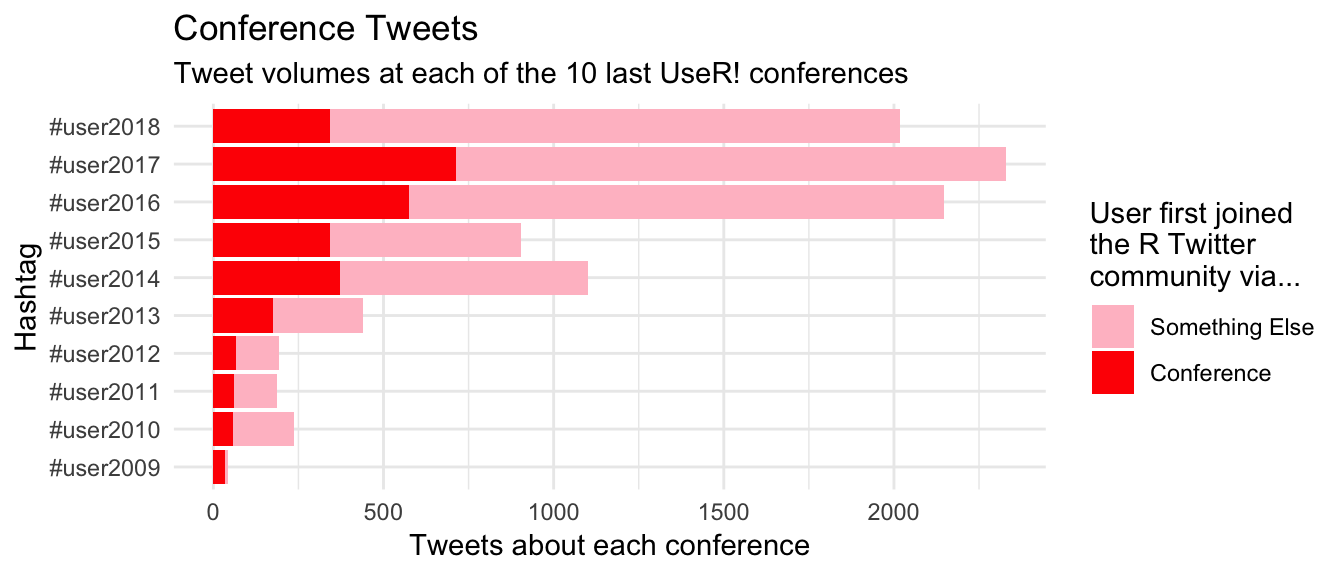
New users are certainly making an impact on the volume of tweets, but the majority of tweets at conferences are being written by people who joined the R Twitter community some time before their first tweet about a conference.
Next steps
This was fun, and I learned a little bit about how new users find their way into the R Twitter community. In my next post I’ll be diving into social network analysis to see if I can find a bit more structure and identify some sub-communities.
I’ll also be looking to bring in more datasets - CRAN and GitHub collaboration data are definitely on my wishlist, as well as the various email lists and anything else I can get my hands on!